RFM-Analyse und User Clustering mit BigQuery ML
1. Über das RFM-Modell
Das Ziel der RFM-Analyse besteht darin, Nutzer zu identifizieren, die auf Grundlage ihres vergangenen Verhaltens eine hohe Wahrscheinlichkeit aufweisen, auf zukünftige Marketingmaßnahmen zu reagieren. Hierzu werden der potenzielle Wertbeitrag und die Relevanz einzelner Nutzer anhand ihres vergangenen Kaufverhaltens durch ein Scoring beurteilt. Der sich aus dem Scoring-Verfahren ergeben Wert lässt sich anschließend für die Optimierung von Marketingmaßnahmen in den einzelnen Marketing-Kanälen (z. B. Google Ads) nutzen.

Im Scoring-Verfahren der RFM-Analyse werden Nutzer hinsichtlich der Kennzahlen Recency (Aktualität), Frequency (Häufigkeit) und Monetary (Umsatz) klassifiziert und anschließend in entsprechende Segmente (Cluster) unterteilt.
Die Recency gibt die Zeitspanne an, wann das letzte Mal durch den entsprechenden Nutzer Umsatz generiert wurde. Je größer der zeitliche Abstand, desto unwahrscheinlicher ist die Interaktion mit einer zukünftigen Marketingmaßnahme (z. B. Search/ Display Ad). Anhand der Frequency wird die Häufigkeit ermittelt, mit der ein Kunde in einem bestimmten Betrachtungszeitraum Umsatz generiert hat. Wenn Kunden häufig einkaufen, dann ist die Wahrscheinlichkeit für eine positive Reaktion auf eine Marketingmaßnahme deutlich höher als bei einem Kunden, der eher selten kauft. Der Geldwert (Monetary) bezieht sich auf den mit dem Kunden erzielten Umsatz im Betrachtungszeitraum. Höhere Umsätze sind ein Indiz für eine bessere Reaktion auf bisherige Marketingmaßnahmen. Nutzer mit hohen Umsätzen werden grundsätzlich mit einem höheren Customer Lifetime Value (CLV) ausgewiesen. Bei steigendem CLV erhöht sich dabei entweder der Return on Invest (ROI) durch die Marketingmaßnahme oder das zur Verfügung stehende Budget.
2. Grenzen und Optimierungspotenziale
Die RFM-Analyse ist einfach durchzuführen, auf ein breites Spektrum von Geschäftsmodellen anwendbar und daher ein bewährtes Einstiegsmodell, um nicht-performante Nutzergruppen zu identifizieren und für zukünftige Marketingmaßnahmen auszuschließen. Jedoch birgt die RFM-Analyse Gefahr, hochperformante Cluster mit Werbung regelrecht zu penetrieren, diese dadurch abzuschrecken und eine gewisse Anzahl wertschöpfender Nutzergruppen auszuschließen. Zudem sollte beachtet werden, dass keine Prognosen über zukünftiges Kaufverhalten der Segmente getroffen werden können, sondern eine Abwägung anhand historischer Daten stattfindet. An diesem Punkt gerät die RFM-Analyse an ihre Grenzen. Mit BigQuery ML stehen jedoch eine Reihe statistischer Verfahren und Machine Learning Modelle zur Verfügung, wodurch sich das Modell laufend optimieren und automatisieren lässt. Im Folgenden stellen wir einen erweiterten Ansatz für die RFM-Clusteranalyse durch eine Optimierung mit dem k-Means Algorithmus dar.
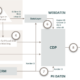
3. Aufbau eines RFM Modells und Aktivierung der Daten mit BigQuery

① Export der GA4- und Google Ads Daten
Über ein Product Linking werden die Rohdaten aus Google Analytics 4 und Google Ads täglich exportiert und in einem BigQuery Table abgelegt.
② Erstellung des RFM-Modells
Für die Zusammenführung der Daten wird die user_pseudo_id (client_id) als Join-Key verwendet. In Kombination mit dem aktuellsten event_timestamp aus dem ecommerce-object der letzten Transaktion stellt sie die Recency (Aktualität) für den Kauf eines spezifischen Nutzers dar. Um die Frequency (Häufigkeit) von Transaktionen für einen bestimmten Nutzer zu ermitteln, wird die Anzahl aller Transaktionen (total_ events) im Betrachtungszeitraum aufsummiert. Der Wert Monetary (Geldwert) wird aus dem Revenue aller Transaktionen im Betrachtungszeitraum gebildet und als Customer Lifetime Value (CLV) ausgewiesen. Anschließend werden die ermittelten Werte für R (Recency) und FM (Frequency, Monetary) aller Nutzer anhand ihrer einzelnen user_pseudo_id in Verbindung mit dem event_timestamp für jeden spezifischen Nutzer dargestellt und als RFM-Modell in ein BigQuery Table überliefert.
Falls verfügbar, sollte die Verwendung einer internen User Id, welche einen realen Nutzer identifiziert, bevorzugt werden. Da die user_pseudo_id randomisiert ermittelt und über den Browser gesetzt wird, dient sie lediglich der Identifikation des Endgerätes/Browsers und nicht dem Nutzer selbst. Sie lässt sich somit direkt durch den Nutzer löschen oder durch Anti-Tracking Maßnahmen von Browser Anbietern als Identifier zeitlich begrenzen.
③ Cluster-Analyse mit dem k-Means-Algorithmus
Die einzelnen user_pseudo_ids oder user_ids werden nun auf Grundlage des RFM-Modells mit dem k-Means Modell in eine gegebene Anzahl homogener Cluster unterteilt. Anschließend wird der gclid (Google Click Identifier) sowie das Keyword aus den Google Ads Rohdaten mit der spezifischen user_pseudo_id gejoint. Der gclid-Parameter wird automatisch vom Google Ad Network bei Anzeigenklick in der URL übergeben. So lassen sich die Kampagne und andere Attribute des Klicks (bspw. Keywords) mit Bezug zur Anzeige ermitteln und diese zuordnen.
Der k-Means-Algorithmus dient der Vektorquantisierung und ist eines der am häufigsten verwendeten Verfahren zur Gruppierung von Objekten (Clusteranalyse). Mit seiner Hilfe lässt sich eine bestimmte Anzahl von Objekten in homogene Gruppen unterteilen. Ziel der Clusterung ist es, dass die verschiedenen Objekte innerhalb einer Gruppe sich möglichst ähnlich sind. Der Algorithmus nähert sich dabei durch sich ständig wiederholende Neuberechnungen den jeweiligen Clusterzentren an, bis keine signifikante Veränderung mehr stattfindet.
Die optimale Anzahl an Clustern lässt sich u. a. mit der sog. “Elbow Function“ ermitteln. Die Verwendung des „Elbows“ oder dem „Knick in der Kurve“ ist eine übliche Heuristik in der mathematischen Optimierung, um einen Punkt zu ermitteln, an dem das Hinzufügen eines weiteren Clusters nicht zu einer wesentlich besseren Modellierung der Daten führt.
④ Auslesen der User Pseudo Id (Client Id)
Der auf der Website implementierte Google Tag Manager liest die Client Id aus dem ga_ Cookie des Browser aus.
⑤ Synchronisierung der Informationen
Anschließend wird über eine Cloud Function die nutzerspezifische User Pseudo Id (Client Id) an BigQuery übermittelt, wo sie mit den Cluster-Informationen synchronisiert wird.
⑥ Übergabe des RFM Clusters
Über eine Cloud Function wird das nutzerspezifische RFM Cluster aus der k-Means Clusteranalyse an den Google Tag Manager übergeben.
⑦ Anreicherung des dataLayers
Der Google Tag Manager reichert den dataLayer mit den Informationen über das RFM-Cluster des Nutzers an.
⑧ Übermittlung der Cluster an Marketing Tools
Der dataLayer.push triggert das Google Ads Marketing Tag, welches mit den Cluster-Informationen für die spezifische gclid angereicht wird und die Daten an die Google Ads Server übermittelt.
4. Schlusswort
Die RFM-Analyse ermöglicht einen einfachen Start in die Clusteranalyse performanter Nutzer und verschafft somit einen ersten Eindruck über das generelle Kaufverhalten spezifischer Nutzergruppen. Sie bietet somit einen guten Ausgangspunkt für Pricing-Strategien im Remarketing, indem auf Grundlage der ermittelten Cluster unterschiedliche Remarketing-Listen gebildet werden können. Die gewählte Marketingstrategie lässt sich anhand verhaltensbasierter Nutzergruppen prüfen und gezielter ausrichten.
Die klassische RFM-Analyse gerät jedoch schnell an ihre Grenzen und sollte daher einen Ausgangspunkt darstellen und von Zeit zu Zeit durch weitere Optimierungsvariablen erweitert werden, um an Aussagekraft und Reliabilität zu gewinnen. Hierzu eignen sich Verfahren des maschinellen Lernens, die das Modell laufend optimieren.