Data Warehousing mit Snowflake
Nutzen Unternehmen die Google Cloud, liegt der Gedanke nahe, auch BigQuery als zentrale Datenschnittstelle für das Data Warehousing der Daten zu nutzen. Das gilt auch für andere Cloud-Anbieter wie Amazon Web Services (AWS) oder Microsoft Azure, die ebenfalls Data Warehouse-Lösungen und komplementäre Funktionen für die Datenmodellierung zur Verfügung stellen. Die Lösungen haben flexible Preismodelle und eine Vielzahl von zusätzlichen Services, die gerade für kleine bis mittelständische Unternehmen ein attraktives Angebot darstellen. Snowflake bietet spezialisierte Lösungen mit vielen Funktionen für Data Warehousing an und wird in der Infrastruktur der bekannten Cloud-Anbieter installiert und betrieben. Es gilt zu untersuchen, ob Snowflake mit seinen Funktionen für Unternehmen einen Mehrwert im Vergleich zu den von den Cloud-Anbietern bereitgestellten Datenbanken für Data Warehousing bietet.
In diesem Blogbeitrag wird das Data Warehouse der Snowflake Data Cloud den Data Warehouse-Lösungen (z.B. BigQuery) von etablierten Cloud-Anbietern gegenübergestellt und aufgezeigt, wie die Integration in eine bestehende Cloud-Architektur dieser Cloud-Anbieter vollzogen werden kann.
1. Aufbau der Snowflake Data Cloud
Bekanntheit im Markt erlangte Snowflake als Cloud Data Warehouse. Im Laufe der letzten Jahre haben sich die Anforderungen an Cloud Data-Plattformen jedoch stark weiterentwickelt. Hierfür bietet Snowflake mit seiner Data Platform klare Vorteile, die durch die unterschiedlichsten Workloads nach einem “Pay per Use”-Bezahlmodell, wie auch aus der Google Cloud bekannt, bedient werden können. Als SaaS (Software as a Service) ohne eigene Cloud-Infrastruktur ist Snowflake jedoch abhängig von einer bestehenden Cloud-Umgebung, in die sie integriert wird.

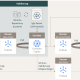
Abbildung 1: Snowflake-Architektur (Übersicht)
Die Snowflake Data Cloud besteht aus drei Schichten, den sogenannten Layern. Wie in vielen Data Clouds wird auch in der Snowflake-Architektur eine Trennung zwischen Datenspeicherung (Storage) und Rechenleistung (Compute) vorgenommen. Einzelne Snowflake-Instanzen werden übergeordnet von einem Service Layer gesteuert. Um ein besseres Verständnis dafür zu entwickeln, in welcher wechselseitigen Beziehung die unterschiedlichen Layer zueinander stehen und welche Aufgaben diese erfüllen, werden diese im folgenden Kapitel genauer vorgestellt.
1.1 Service Layer (Workflow Administration)

Abbildung 2: Snowflake Cloud Service Layer
Alle Interaktionen mit Daten in einer Snowflake-Instanz beginnen im sogenannten Cloud Service Layer. Dieser besteht aus einer Sammlung von Diensten, die Aktivitäten wie Authentifizierung, Zugriffe und Verschlüsselungen koordinieren. Er umfasst auch Verwaltungsfunktionen für Infrastruktur und Metadaten sowie für die Analyse und Optimierung von Abfragen. Jedes Mal, wenn sich ein Nutzer in die Snowflake Data Cloud einloggt, wird seine Authentifizierungs-Anfrage vom Service Layer verarbeitet. Führt der Nutzer anschließend eine SQL-Abfrage in einer Daten-Instanz durch, wird die Abfrage an den Optimizer des Service Layers gesendet, bevor sie zur Verarbeitung an den Compute Layer weitergeleitet wird. Der Service Layer ermöglicht somit als Schnittstelle zum SQL-Client für Data Definition Language (DDL) und Data Manipulation Language (DML) Operationen auf Grundlage der Daten einzelner Snowflake Storage-Instanzen.
Zudem verwaltet der Service Layer die Datensicherheit und läuft über mehrere Verfügbarkeitszonen, je nach unterstützter Region des gewählten Cloud-Anbieters für die Infrastruktur. Anschließend wird eine zwischengespeicherte Kopie der ausgeführten Abfrageergebnisse gesichert und für die Abfrageoptimierung oder Datenfilterung im Meta-Cache gesichert.
1.2 Compute Layer (Rechenleistung)

Abbildung 3: Snowflake Compute Layer
Die eigentliche Rechenleistung findet in den sog. “Virtual Warehouses” des Snowflake Compute Layers statt. Ein virtuelles Warehouse basiert auf einem dynamischen Cluster von Rechenressourcen, der aus CPU-Speicher und temporärem Speicher besteht. Bei der Erstellung eines virtuellen Warehouse in Snowflake werden Rechencluster (Virtual Machines) in der Cloud verwendet, die im Hintergrund für die Auslastung der Rechenressourcen vom gewählten Vendor bereitgestellt werden. Der Server-Standort des virtuellen Warehouse variiert je nach verwendetem Cloud-Anbieter. Für die meisten SQL-Abfragen und alle DML-Vorgänge, einschließlich des Ladens und Entladens von Daten in Tabellen sowie der Aktualisierung von Tabellenzeilen, ist eine Mindestanzahl von permanent verfügbaren Slots erforderlich, die nach Bedarf aufskaliert werden kann.
Durch die Trennung von Speicher und Rechenleistung kann jedes virtuelle Warehouse auf Daten des gleichen Snowflake Storage zugreifen, ohne dass es zu Konflikten kommt. Jedes virtuelle Snowflake Warehouse arbeitet unabhängig und teilt keine Rechenressourcen mit anderen Instanzen.

Abbildung 4: Snowflake Warehouse-Größen und Credit-Verbrauch
Ein Snowflake-Rechencluster wird durch seine Größe definiert, wobei die Größe der Anzahl der Server im Cluster des virtuellen Warehouse entspricht. Bei jeder Erhöhung der Größe des virtuellen Lagers erhöht sich die Anzahl der Server pro Cluster um den Faktor 2 bis zu einer Größe von 6X-Large. Der Verbrauch an Credits pro Stunde steigt ebenfalls um den Faktor 2. SnowflakeCredits werden verwendet, um für den Verbrauch von Ressourcen auf Snowflake zu bezahlen. Ein Snowflake-Credit wird nur dann verbraucht, wenn ein virtuelles Warehouse belastet wird, der Service Layer Anfragen bearbeitet oder serverlose Funktionen verwendet werden. Das Pricing-Modell für den Storage Layer und die Credits des Compute Layers in Snowflake wird in Kapitel 3.3 dieses Whitepapers im Rahmen eines Wettbewerbsvergleiches beleuchtet.
1.3 Storage Layer (Datenspeicher)

Abbildung 5: Snowflake Storage Layer
Der zentralisierte Storage Layer von Snowflake enthält alle Daten, einschließlich strukturierter und halbstrukturierter Daten. Diese werden in einem komprimierten, spaltenorientierten Format reorganisiert und im Storage der Snowflake-Instanz gespeichert und verwaltet. Jede Snowflake-Instanz besteht aus einem Schema oder mehreren Schemata, d. h. einer logischen Gruppierung von Datenbankobjekten wie Tabellen und Views.
Die gespeicherten Daten sind in Snowflake immer komprimiert, verschlüsselt und automatisch in Mikropartitionen (komprimiertes Spaltenformat) organisiert. Dies gestaltet die Extraktion von Metadaten und die Abfrageverarbeitung einfacher und effizienter.
Der Storage Layer von Snowflake wird manchmal auch als sog. „Remote Disk Layer“ bezeichnet. Grund dafür ist, dass das zugrunde liegende Dateisystem in der AWS Cloud, in Microsoft Azure oder in der Google Cloud implementiert wird. Der spezifische Anbieter für die Datenspeicherung wird bei Erstellung des Snowflake-Kontos ausgewählt. Snowflake setzt keine Deckelung für die Menge der Daten, die in der Instanz gespeichert werden, oder für die Anzahl der Datenbanken und Datenbankobjekte an. Die Vergrößerung oder Verkleinerung des Storage in einem Snowflake-Konto hat keinen Einfluss auf die Größe des virtuellen Warehouse, da sie unabhängig voneinander und von der Cloud Service-Ebene skaliert werden.
Um einen besseren Überblick über die Besonderheiten wie auch die Unterschiede zwischen den einzelnen Cloud-Anbietern bei der Wahl einer geeigneten Cloud-Infrastruktur für Snowflake zu bekommen, stellen wir im nachfolgenden Kapitel die hauseigenen Data Warehouse-Lösungen der Cloud-Vendoren Microsoft, Google und AWS auf Grundlage vordefinierter Kriterien in einem Wettbewerbsvergleich gegenüber.
2. Data Warehousing mit Snowflake im Wettbewerbsvergleich
Die meisten Cloud-Vendoren bieten bereits eigene Data Warehouse-Lösungen für ihre Cloud-Infrastruktur an, die für die Integration in die eigene Cloud-Umgebung optimiert sind. Snowflake hat mit den modernen Cloud Data WarehouseLösungen bekannter Vendoren viele Gemeinsamkeiten, z. B. spaltenbasierte Speicherung, Massive Parallel Processing (MPP) und kostenbasiertes Query Management. Es gibt aber Unterschiede in Funktionsumfang und Preismodellierung, die bei der Wahl des passenden Anbieters und seiner Infrastruktur beachtet werden sollten. Nachfolgend werden Snowflake die Data Warehouse-Lösungen der Cloud-Anbieter Google, AWS und Microsoft anhand ihrer Architektur, administrativen Funktionen, allgemeinen Performance und Skalierbarkeit sowie ihrer angebotenen Preismodelle gegenübergestellt.
2.1 Architektur und Administration
Cloud Data Warehouses unterscheiden sich darin, ob sie Speicher (Storage) und Rechenleistung (Compute) trennen, wie stark sie Daten und Rechenleistung isolieren und auf welcher CloudInfrastruktur sie betrieben werden können. In Folgendem werden die Cloud Data Warehouse-Lösungen Google BigQuery, Amazon Redshift und Microsoft Azure hinsichtlich ihrer technischen Architektur und Administration Snowflake gegenübergestellt, um Unterschiede und Gemeinsamkeiten aufzuzeigen.

Abbildung 6: Data Warehousing mit Snowflake im Wettbewerbsvergleich: Architektur und Administration
Einer der Hauptunterschiede zwischen Snowflake und den hauseigenen Data Warehouse-Lösungen der Cloud-Vendoren ist, dass sie unterschiedlich verkauft werden. Snowflake ist eine SaaSPlattform (Software as a Service) und kann auf der Infrastruktur anderer Cloud-Anbieter betrieben werden. Die Multi-TenancyLösung mit gemeinsam genutzten Ressourcen erfordert, dass die Daten über eine Virtual Private Cloud (VPC) in die Snowflake Cloud verschoben werden.
Auch BigQuery und Azure Synapse sind Multi-Tenancy-Lösungen, in welchen gemeinsam genutzte Ressourcen als „Slots“ zugewiesen werden und eine virtuelle CPU darstellen, die SQL ausführt. Durch horizontales Auto-Scaling bestimmen beide Lösungen automatisch, wie viele Slots einer Abfrage benötigt werden. Gegründet als Query Engine auf einer “serverless Architektur“, kann BigQuery nicht als klassisches Data Warehouse bezeichnet werden, da sich der Funktionsumfang von BigQuery über die Jahre erst entwickelt hat und die Rechenleistung und Funktionen vielmehr über Services der GCP an sich ermöglicht werden. Redshift hingegen besitzt als erste Cloud-DW in der Gruppe die älteste Architektur.
Diese war nicht auf die Trennung von Speicherung und Berechnung ausgelegt. Zwar gibt es inzwischen RA3-Knoten, die eine Skalierung der Rechenleistung ermöglichen und nur Daten zwischenspeichern, die auch lokal benötigt werden, doch wird auch hier die gesamte Rechenleistung beansprucht. Es ist nicht möglich, verschiedene Workloads auf den gleichen Daten zu trennen und zu isolieren, wodurch Redshift hinter anderen entkoppelten Speicher-/Rechnerarchitekturen zurückbleibt. Redshift wird als isolierter Tenant pro Kunde ausgeführt und, im Gegensatz zu den anderen Cloud Data Warehouses, in einer VPC bereitgestellt.
2.2 Performance und Skalierbarkeit

Abbildung 7: Data Warehousing mit Snowflake im Wettbewerbsvergleich: Performance und Skalierbarkeit
Dank Auto-Scaling zeigen sowohl Snowflake als auch BigQuery und Azure Synapse eine gute Leistung bei verschiedenen Workloads. Snowflake lässt sich sowohl in Bezug auf das Datenvolumen als auch auf die gleichzeitige Abfragegeschwindigkeit skalieren. Die Trennung von Storage und Compute unterstützt die Größenanpassung von Clustern ohne Ausfallzeiten und darüber hinaus das horizontale Skalieren für eine höhere Abfragevergleichbarkeit während Abfrage-Peaks.
Aber auch BigQuery und Azure Synapse lassen sich sehr gut auf große Datenmengen skalieren und weisen bei Bedarf im Hintergrund automatisch mehr Rechenressourcen in Form von Slots mittels Auto-Scaling zu.
Redshift ist in seiner Skalierbarkeit begrenzt, da es selbst mit RA3 nicht in der Lage ist, verschiedene Workloads auf ComputeCluster zu verteilen. Es kann zwar automatisch auf bis zu 15 Cluster skaliert werden, standardmäßig jedoch maximal 50 Abfragen über alle Cluster hinweg verarbeiten. Redshift bietet einen ErgebnisCache zur Beschleunigung von sich wiederholenden Abfragen und verfügt, je nach Dienstebene und Ressourcenklasse, über bessere Compute-Tuning-Optionen als andere Vendoren. Da Redshift im Vergleich zu den anderen Cloud Data Warehouses allerdings nur begrenzt eine Entkopplung von Speicher und Rechenleistung bietet, unterstützt es keine Isolierung einzelner Workloads, woraus Leistungseinbrüche bei der Ausführung mehrerer Workloads im Wettbewerb um verfügbare Ressourcen resultieren können.
2.3 Pricing

Abbildung 8: Data Warehousing mit Snowflake im Wettbewerbsvergleich: Pricing
Snowflake verwendet ein zeitbasiertes Preismodell für Rechenressourcen, welches Nutzern die Ausführungszeit pro Sekunde berechnet, nicht aber die während der Berechnung evaluierte Datenmenge. Es stehen verschiedene Optionen für reservierte oder On-Demand-Speicher in Form von fünf TarifModellen zur Verfügung. Die Modelle richten sich nach Volumen und Art der Daten, der Region sowie der verwendeten CloudPlattform und unterscheiden sich teils stark voneinander. Eine Pricing-Übersicht jedes Anbieters ist jeweils unter dem in der Abbildung oben dargestellten Link zu finden.
Die Kosten für einen Snowflake-Credit beginnen bei $2, je nach Region, dem bevorzugten Cloud-Anbieter (Azure, AWS, Google Cloud Platform) und der gewählten Snowflake Platform-Version. Für jede der genannten Data Warehouse-Größen gibt es einen speziellen Compute Credit. Mit zunehmender Größe variiert auch der Verbrauch der Credits.
BigQuery arbeitet entweder mit einem „On-Demand” Pricing, bei dem die Zuweisung von Slots vollständig in den Händen von BigQuery und des gemeinsam genutzten Ressourcen-Pools liegt, oder mit einem Pauschalpreis-Modell, bei dem Slots im Voraus reserviert werden. Bei reservierten Slots ist die Kontrolle über die Rechenressourcen größer, wodurch die Skalierung besser vorhersehbar wird. AWS Redshift und Azure Synapse hingegen berechnen die Rechenleistung auf Stundenbasis. Wenn das Data Warehouse also bspw. nur 10 Stunden in einem Monat aktiv ist, werden auch nur diese 10 Stunden abgerechnet.
3. Integration von Snowflake in eine bestehende Cloud-Umgebung
Bei der Wahl der passenden Cloud-Infrastruktur für Snowflake sollte neben genannten Aspekten wie Skalierbarkeit, Performance und Pricing auch die Auswahl an komplementären Services für die Datenanalyse und Datenverarbeitung und die weitere ToolLandschaft für eine reibungslose ETL-Planung berücksichtigt werden. Im folgenden Kapitel stellen wir für die Cloud-Vendoren Amazon AWS, Microsoft Azure und Google Cloud Platform einen architektonischen Ansatz für die Integration von Snowflake als zentrales Data Warehouse in der jeweiligen Cloud-Umgebung vor. bietet, unterstützt es keine Isolierung einzelner Workloads, woraus Leistungseinbrüche bei der Ausführung mehrerer Workloads im Wettbewerb um verfügbare Ressourcen resultieren können.
3.1 Snowflake in der Google Cloud-Umgebung
Die Google Cloud Platform (GCP) besteht aus einer Reihe von Cloud Computing-Diensten auf Basis der Infrastruktur, die Google intern für Produkte wie Google Search und YouTube nutzt. Ein flexible Kostenstruktur und zahlreiche Konnektoren bieten niedrige Einstiegshürden. Das folgende Schaubild zeigt beispielhaft eine Data Pipeline in der Google Cloud Platform unter Verwendung von Snowflake als Cloud Data Warehouse für ein zentrales Datenmanagement.

Abbildung 9: Snowflake in der Google Cloud-Umgebung – Architektur-Plot
COLLECT – PROCESS – INGEST
Die Extrahierung und Integration der Daten wird je nach Art des Quellsystems durch einen Streaming- oder Batch-Service initiiert und gemanagt. Mit dem Service PubSub bietet die GCP einen asynchronen Messaging-Dienst zum Managen und Weiterleiten von Streaming-Requests. Jobs für Batch-Uploads aus Tools und Datenbanken lassen sich beispielsweise über das ETL-Tool Dataflow einfach erstellen und verwalten. Zur Übermittlung der Daten in die Snowflake-Instanz wird ein temporärer ObjektSpeicher benötigt, in dem die Daten zwischengespeichert werden. Hierfür bietet die GCP den sog. Cloud-Storage an, der die Daten direkt an Snowflake übermittelt. Über den Service Dataproc steht zusätzlich ein Dienst für die Ausführung von Apache Spark und über Dataprep ein Dienst für die Datenbereinigung unstrukturierter Daten zur Verfügung.
STORE – ANALYZE – ACTIVATE
Für die Weiterverarbeitung, Analyse und Modellierung von Daten bietet die GCP zahlreiche Services, welche direkt von Snowflake genutzt werden können. Neben Data Science-Funktionalitäten wie Data Lab oder TensorFlow stellt die GCP eine eigene AI Platform (Vertex AI) bereit, in der Modelle mit Datensätzen erstellt und trainiert werden können. Gerade für anschließende BI-Analysen und Dashboarding eignet sich die Google Cloud mit ihren Tools Data Studio und Looker besonders gut. Auch die Komplementarität zu Werbeprodukten aus dem Google-Universum wie bspw. Youtube und Google Ads ist nicht außer Acht zu lassen. In den Tools können die Daten durch native Konnektoren und TransferServices direkt zur Aktivierung genutzt werden.
3.2 Snowflake in der AWS Cloud-Umgebung
Amazon Web Services (AWS) ist eine Cloud Computing-Plattform, die von Amazon zur Verfügung gestellt wird. Die ersten AWSAngebote wurden im Jahr 2006 ins Leben gerufen, um OnlineDienste für Websites und clientseitige Anwendungen bereitzustellen. Mittlerweile ist der Service in 190 Ländern weltweit verfügbar. Das folgende Schaubild zeigt beispielhaft eine Data Pipeline in der AWS Cloud-Umgebung unter Verwendung von Snowflake als Cloud Data Warehouse für ein zentrales Datenmanagement.

Abbildung 10: Snowflake in der AWS Cloud-Umgebung – Architektur-Plot
COLLECT – PROCESS – INGEST
Auch bei AWS wird die Extrahierung und Integration der Daten je nach Art des Quellsystems durch einen Streaming- oder Batch-Service initiiert und gemanagt. Mit dem Kinsesis Stream bietet AWS einen serverless Streaming-Dienst, der das Erfassen, Verarbeiten und Weiterleiten von Streaming-Requests in jeder Größenordnung managt. Für die Planung von Batch-Uploads aus Tools und Datenbanken kann der Service AWS Batch verwendet werden. Zur Übermittlung der Daten in die Snowflake-Instanz wird ein temporärer Objekt-Speicher benötigt, indem die Daten zwischengespeichert werden. Hierfür bietet die AWS CloudUmgebung den Service S3 Glacier, welcher die Daten direkt an Snowflake übermittelt. Über den Service AWS EMR steht zusätzlich ein Dienst für die Ausführung von Apache Spark zur Verfügung. AWS Glue ermöglicht als ETL-Workflow Management Tool, die einzelnen Jobs zu konsolidieren und über einen Konnektor direkt an die jeweilige Snowflake Storage-Instanz zu übermitteln.
STORE – ANALYZE – ACTIVATE
Für die Weiterverarbeitung, Analyse und Modellierung von Daten stellt auch die AWS Cloud-Umgebung eine Vielzahl von Services zur Verfügung, welche direkt von Snowflake genutzt werden können. Neben Data Science-Funktionalitäten wie Glue Databrew oder einer eigenen TensorFlow Application bietet AWS mit SageMaker als Pendant zur Vertex AI der GCP ebenfalls eine eigene AI Platform, in der Modelle mit Datensätzen erstellt und trainiert werden können. Sehr interessant ist in diesem Zusammenhang auch der Service AWS Personalize, über den sich personalisierte Empfehlungen für die Kundensätze aus den ML-Pipelines entwickeln und aussteuern lassen.
3.3 Snowflake in der Microsoft Azure Cloud-Umgebung
Microsoft Azure ist eine Cloud Computing-Plattform von Microsoft, die sich in erster Linie als Plattform für die Entwicklung von Software etabliert, aber über die Jahre hinweg ebenfalls als Big Player unter den Data Clouds entwickelt hat. Auch die Data Cloud Services von Azure lassen sich komplementär mit Snowflake nutzen. Bei der Abwägung eines Einsatzes von Azure als mögliche technologische Infrastruktur für Snowflake soll das folgende Schaubild helfen, das beispielhaft eine Data Pipeline in der Azure Cloud-Umgebung unter Verwendung von Snowflake als Cloud Data Warehouse für ein zentrales Datenmanagement darstellt.

Abbildung 11: Snowflake in der Microsoft Azure Cloud-Umgebung – Architektur-Plot
COLLECT – PROCESS – INGEST
Wie auch in der Google Cloud und AWS Cloud, wird die Extrahierung und Integration der Daten je nach Art des Quellsystems durch einen Streaming- oder Batch-Service eingeleitet und gehandhabt. Mit dem Event Hub bietet Azure eine Möglichkeit zum Konsolidieren, Verarbeiten und Weiterleiten von Streaming-Requests. Für die Planung von Batch-Uploads aus Tools und Datenbanken kann der Service Azur Batch verwendet werden. Zur Übermittlung der Daten in die Snowflake-Instanz wird ein temporärer Objekt-Speicher benötigt, in dem die Daten zwischengespeichert werden. Hierfür bietet die Azure CloudUmgebung den Azure Blob Storage, welcher die Daten an das ETL-Management Tool Data Factory weiterleitet, das Workflows konsolidiert und an Snowflake übermittelt. Für Apache Spark Workloads stellt Azure einen nativen Konnektor zur Verfügung
STORE – ANALYZE – ACTIVATE
Für die Weiterverarbeitung, Analyse und Modellierung von Daten stellt die Azure Cloud-Umgebung ebenfalls einige Services zur Verfügung, welche direkt von Snowflake genutzt werden können. Jedoch macht sich hier bemerkbar, dass die Service-Landschaft im Vergleich zu der GCP und der AWS-Cloud noch ausbaufähig ist. Neben Data Science-Funktionalitäten wie Databricks für die Arbeit mit Spark bietet Azure mit Azure ML eine eigene ML-Plattform, in der Modelle mit Datensätzen erstellt und trainiert werden können. Zurzeit stellt Azure jedoch keinen built-in-Konnektor für die Anbindung von Snowflake-Instanzen zur Verfügung. Die Anbindung muss demnach über den Snowflake Py-Connector erfolgen. Auch Azure bietet mit PowerBI einen leistungsstarken BI-Service, um Erkenntnisse für die Datenaktivierung zu gewinnen.
4. Schlusswort
Die Snowflake Data Platform ermöglicht das Ausführen von Workloads und Anwendungen auf der Infrastruktur etablierter Cloud-Anbieter, einschließlich Services wie Data Warehousing, Data Lakes, Data Science-Funktionen, erweiterte Analysen und Business Intelligence Software. Einer der größten Vorteile von Snowflake selbst ist seine Unabhängigkeit zu der jeweiligen Cloud-Plattform, auf der es eingesetzt wird. Die Daten lassen sich sowohl über Regionen als auch über verschiedene CloudAnbieter hinweg in dedizierte Instanzen verteilen, sodass die Nutzung von mehreren Clouds kombiniert werden kann. Vor allem, wenn in Unternehmen bereits eine etablierte und historisch gewachsene Cloud-Infrastruktur besteht, diese sich aus analytischer und marketingtechnischer Sicht jedoch nicht optimal eignet, kann die Integration von Snowflake Synergien zwischen Services einzelner Plattformen schaffen.
Eine Data Warehouse-Lösung eines etablierten Cloud-Anbieters zu wählen, mag auf den ersten Blick sinnvoll erscheinen, wenn für Marketing- und Analytics-Aktivitäten ebenfalls Services dieser Cloud-Umgebung genutzt werden. Es empfiehlt sich allerdings abzuwägen, ob Snowflake mit seinem Funktionsumfang, seiner Bedienoberfläche und als zentrale Datenschnittstelle für alle Unternehmensbereiche und Technologien das Data Warehousing vereinfachen kann.