Aufbau einer Recommendation Engine in der Google Cloud Platform (GCP)
Als Recommendation Engine (RE) wird die Technologie hinter Produkt- oder Inhaltsempfehlungen von Content- oder E-Commerce Websites bezeichnet. Das Ziel einer Recommendation Engine ist es, die User Experience zu verbessern, indem sie für den Nutzer relevante Produkte und Inhalte zur richtigen Zeit und auf der richtigen Seite anbietet. Es ist kein Geheimnis, dass eine individuelle Ansprache das Einkaufserlebnis von Interessenten und die Kundenbindung fördert. Mittlerweile gibt es eine Viel- zahl an Marketingkanälen, welche zahlreiche Kontaktpunkte mit Interessenten eröffnen. Eine individuelle Ansprache durch Produkt- oder Content-Empfehlungen stellen hierfür eine effektive Maßnahme dar. Recommendation Engines helfen Kunden, Produkte zu entdecken, die ihren Vorstellungen und Bedürfnissen entsprechen, indem sie bereits gekaufte Produkte ergänzen oder Kaufprofile homogener Nutzer vorschlagen.
Viele Unternehmen haben deshalb Recommendation Engines lizenziert und eingekauft. Um das volle Potenzial personalisierter Recommendations auszuschöpfen, ist es notwendig, sich vom Wettbewerb abzuheben. Einen wahren Wettbewerbsvorteil durch vorgefertigte End-to-End Lösungen zu erlangen, ist jedoch nahezu unmöglich. Welche Möglichkeiten moderne Cloud Technologien bieten, um Recommendation Engines auf das Unternehmen abzustimmen, erfahren Sie in diesem Blogbeitrag.
„Ich höre immer wieder, dass individuelle Recommendations kein Thema mehr in Unternehmen seien, denn Recommendation Engines sind bereits seit Jahren erfolgreich im Einsatz. Wie kann man sich von seinen Mitbewerbern abheben, wenn man mehr oder weniger die gleichen Lösungen einsetzt? One-size-fits-all kann für diese sehr wichtige Marketingmaßnahme nicht der richtige Ansatz sein. Das Potenzial und der Wettbewerbsvorteil liegen nicht bei bestehenden Lösungen, sondern in der Cloud.“
– Marcus Stade
1. Arten von Empfehlungsmodellen
Grundsätzlich lassen sich Recommendation Engines aufgrund ihrer Funktionsweise in drei unterschiedliche Typen von Empfehlungsmodellen unterteilen:

Collaborative filtering
Beim kollaborativen Filtern werden Daten über das Verhalten, die Aktivitäten und Vorlieben von Nutzern gesammelt, um vorherzusagen, was ein Nutzer aufgrund seiner Ähnlichkeit mit anderen Nutzern mögen wird.

Content-based filtering
Die inhaltsbasierte Filterung beruht auf dem Prinzip, dass homogene Produkte einer vom Nutzer bevorzugten Produktkategorie ebenfalls interessant für den Nutzer sind. Um Ähnlichkeiten zwischen Artikeln für die Produktempfehlungen zu ermitteln, wird das Profil des Kunden um Präferenzen zu Artikeln und ihrer Beschreibung ergänzt.
Nachteil:
Das System kann nur Produkte oder Inhalte empfehlen, die den Produkten ähneln, die bereits gekauft wurden.

Hybrides Modell
Ein hybrides Modell bezieht sich auf Metadaten (kollaborative Daten) und Transaktionsdaten (inhaltsbasierte Daten). Somit werden sowohl die Interessen des Nutzers (kollaborativ) als auch die Beschreibungen oder Merkmale des Produktes (inhaltsbasiert) berücksichtigt.
2. End-to-End-Lösungen mit der Recommendations AI
Mit der Recommendations AI (kurz Reco AI) bietet die Google Cloud Platform (GCP) eine End-to-End-Lösung für eine Vielzahl von Empfehlungsmodellen. Dies vereinfacht den Aufwand für Aufbau und Integration einer Recommendation Engine, da keine umfangreichen Kenntnisse über maschinelles Lernen, Systemdesign oder Betrieb notwendig sind. Ihr übersichtliches Interface erleichtert gleichzeitig das Monitoring und Testing der ausgespielten Empfehlungen. Neben der einfachen und kostengünstigen Implementierung der Reco AI stellt die Berücksichtigung der einzelnen Phasen in der Customer Journey des Nutzers einen wesentlichen Vorteil dar.
2.1 Anforderungen und Datengrundlage
Die Art der importierten Nutzerereignisse und deren benötigte Datenmenge hängt von dem gewählten Empfehlungsmodell und dem Optimierungsziel ab. Wenn die minimale Datenanforderung erreicht wird, kann mit dem Training des Modells begonnen werden. Das zeitliche Fenster für die Datenaggregierung stellt dabei die maximale Zeitspanne des Lockback Windows für die Reco AI dar. Das Importieren von weiteren historischen Daten nimmt dabei keinen Einfluss auf die Modellqualität.
Auf der Grundlage von Produktkatalogen und historischen Nutzerdaten (Events) erstellt die Reco AI ein Empfehlungsmodell. Um Modelle für das fortlaufende maschinelle Lernen bereitzustellen, benötigt die Reco AI folgende Informationen:
Produktkatalog
Der Produktkatalog ist eine Sammlung von Produkt-Objekten. Er enthält Informationen zu Produkten, die im Onlineshop gelistet sind. Die Katalogdaten haben dabei einen direkten Einfluss auf die Qualität des resultierenden Modells und somit auf die Qualität der von der Reco AI bereitgestellten Empfehlung. Allgemein gilt: Je genauer und spezifischer die Kataloginformationen sind, desto höher ist die Qualität des Modells. Die folgenden Parameter sind verpflichtend für einen Import des Produktkatalogs.
Die offizielle Dokumentation von Google stellt jedoch noch eine Vielzahl optionaler Felder bereit.
| Feld | Beschreibung |
| name | Der eindeutige Ressourcennamen des Produkts. Die Angabe ist für alle Produkt-Methoden außer import erforderlich. |
| id | Die in der Produktdatenbank verwendete Produkt-ID. Das ID-Feld muss für den gesamten Katalog eindeutig sein. Derselbe Wert wird beim Aufzeichnen eines Nutzerereignisses verwendet und auch von der Methode predict zurückgegeben. |
| title | Der Produkttitel aus Ihrer Produktdatenbank. Ein UTF-8-codierter String, welcher auf 1.250 Zeichen begrenzt ist. |
Nutzerereignisse
Die Nutzerereignisse umfassen spezifische Nutzer-Interaktionen (Events) mit Produkten. Dies inkludiert beispielsweise Nutzer, welche nach einem bestimmten Artikel suchen, sich diesen ansehen oder etwas kaufen. Die Messung folgender Events ist verpflichtend für einen Import von Nutzerereignissen:
- add-to-cart
- detail-page-view
- home-page-view
- purchase-complete
2.2 Verfügbare Empfehlungsmodelle
Innerhalb der Reco AI stehen unterschiedliche Typen von Empfehlungsmodellen zur Verfügung. Zurzeit bietet die Plattform jedoch lediglich Modelle für die Optimierung von Produkten auf Grundlage des Content-based-filterings. Im Folgenden werden die verschiedenen Modelltypen kurz vorgestellt:
„Was Ihnen sonst noch gefallen könnte“
Das Modell sagt das nächste Produkt vorher, das ein Nutzer am wahrscheinlichsten ansieht oder kauft. Die Vorhersage basiert auf dem Warenkorbverlauf oder Aufrufverlauf der angegebenen user_id oder visitor_id und der so ermittelten Relevanz eines bestimmten Katalogartikels. Empfehlungen werden normalerweise auf Produktdetailseiten verwendet.
„Häufig zusammen gekauft“
Dieses Modell sagt Artikel vorher, die häufig zusammen mit einem oder mehreren Katalogartikeln in derselben Sitzung erworben werden. Wird normalerweise nach dem Hinzufügen von Artikeln zum Einkaufswagen, auf Produktdetailseiten oder auf der Warenkorbseite angezeigt.
„Empfehlungen für mich“
Das Modell sagt das nächste Produkt vorher, dass ein Nutzer am wahrscheinlichsten ansieht oder kauft. Die Vorhersage basiert auf dem Warenkorbverlauf oder dem Aufrufverlauf der bestimmten user_id oder visitor_id. Wird normalerweise auf der Startseite verwendet.
2.3 Optimierungsziele
Die Machine-Learning (ML) Modelle werden zur Optimierung für ein bestimmtes Ziel erstellt. Das Optimierungsziel bestimmt daher, wie das Modell erstellt und trainiert wird. Jedes Modell-Placement hat ein standardmäßiges Optimierungsziel, welches im Verlauf des Trainings nicht mehr geändert werden kann. Die Reco AI unterstützt folgende Optimierungsziele:
Klickrate (Click Through Rate, CTR)
Durch die Optimierung für die Klickrate werden die Interaktionen mit Produkten gefördert. Die CTR ist das Standard-Optimierungsziel für die Modelltypen „Was Ihnen sonst noch gefallen könnte“ und „Empfehlungen für mich“.
Die CTR berechnet sich aus der Anzahl der Produktdetailansichten, aus einer Empfehlungsübersicht, geteilt durch die Gesamtzahl der Impressionen des jeweiligen Placement-Typs.
Conversion Rate (CVR)
Dieses Modell sagt Artikel vorher, die häufig zusammen mit einem oder mehreren Katalogartikeln in derselben Sitzung erworben werden. Wird normalerweise nach dem Hinzufügen von Artikeln zum Einkaufswagen, auf Produktdetailseiten oder auf der Warenkorbseite angezeigt.
Umsatz pro Sitzung
Diese Metrik beschreibt den Gesamtumsatz für Empfehlungen innerhalb einer Sitzung.
2.4 Technischer Workflow
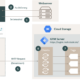
Nachfolgendes Schaubild visualisiert den Prozess der Integration der Recommendation Engine bildlich und erläutert detailliert die einzelnen Prozessschritte. Der technische Workflow veranschaulicht einen von mehreren Lösungsansätzen für die Aussteuerung der von der Recommendations AI ausgelieferten Empfehlungen.

① Einlesen der Produktdaten
Zu Beginn erfolgt das Einlesen (Importieren) der Produktdaten. Als Datenquelle lässt sich ein Google Cloud Storage nutzen, welcher Produktdaten aus dem Google Merchant Center bezieht. Eine direkte Integration der Produktdaten über ein BigQuery Projekt ist ebenfalls möglich. Nach erfolgreichem Einlesen der Produktdaten steht im User-Interface der Reco AI eine Zusammenfassung des fertigen Produktkataloges in Echtzeit zur Verfügung.
② Nutzerereignisse messen und einlesen
Über den auf der Website implementierten GTM-Container werden Produkt-Interaktionen des Nutzers erfasst. Dabei wird das im dataLayer ausgesteuerte Ecommerce-Object über ein spezielles Tag im GTM an die Reco AI übermittelt. Der GTM sendet neben Produktinformationen des jeweiligen Events aus dem dataLayer auch die visitorId als Join-Key für das spätere nutzerspezifische Aussteuern der Empfehlungen. Die Events sind nicht unmittelbar an den Katalog geknüpft. Der Katalog wird auf Tag Ebene eingestellt, wodurch die ID des Produktes (bzw. bei Varianten die Produkt ID der Variante) an die Reco AI übermittelt wird.
③ Auswahl des Empfehlungsmodells
Nach der Einrichtung der Datenquellen für die Produkt- und Nutzerinformationen, muss ein entsprechendes Empfehlungsmodell für das gesetzte Geschäftsziel gewählt werden. Hierbei besteht die Wahl zwischen den in Kapitel 3.2 genannten Modellen.
④ Auswahl des Optimierungsziels (Geschäftsziel)
Wie bereits beschrieben, lassen sich verschiedene Optimierungsziele für das gewählte Empfehlungsmodell festlegen. Wichtig hierbei zu beachten ist, dass, wie auch bei der Wahl des Empfehlungsmodells, das gewählte Optimierungsziel unmittelbaren Einfluss auf die Datenanforderungen nimmt.
⑤ Konfiguration des Geschäftsziels
Nach der Wahl des Optimierungsziels lässt sich dieses nach erweiterten optionalen Kriterien konfigurieren. Darunter fällt bspw. der Grad der Diversifizierung von Ergebnissen. Mit der Anpassung der Diversität wird die Wahrscheinlichkeit reduziert, dass einem Nutzer ähnliche Katalogelemente in der Empfehlungsübersicht angezeigt werden. Es besteht die Wahl zwischen keiner, niedriger (3 Elemente pro Kategorie), mittlerer (2 Elemente pro Kategorie) und einer hohen Diversifizierung (1 Elemente pro Kategorie). Es gilt aber zu beachten, dass mit steigender Diversifizierung auch die Gefahr besteht, gute Empfehlungen auszuschließen.
⑥ Prediction API
Über die Prediction API werden die Vorhersagen von den in der AI Platform gehosteten Modellen abgefragt und anschließend an den GTM ausgeliefert.
⑦ Auslieferung der Empfehlung
Die Auslieferung der Empfehlungen erfolgt über den GTM, der sie über die predict method von der Prediction API per POST message empfängt und in den dataLayer ausliefert. Im dataLayer können die Produktempfehlungen nun über Onsite-Optimierungstools wie bspw. Google Optimize oder einem Shop-Plugin auf der Seite ausgespielt werden.
3. Aufbau einer benutzerdefinierten Recommendation Engine mit BigQuery
In diesem Kapitel wird eine Möglichkeit für den Aufbau einer benutzerdefinierten Recommendation Engine innerhalb BigQuery mithilfe verfügbarer Backend-Dienste/Services der Google Cloud Platform (GCP) beschrieben. Hierzu werden im ersten Schritt Produkt-Moment-Korrelationen anhand von Produkt-/ Warenkorb-Daten aus dem Ecommerce-Transaction-Object gebildet und anschließend durch eine Clusteranalyse mit dem k-Means Algorithmus in homogene Gruppen unterteilt. Mithilfe des XG Boost Algorithmus werden zusätzlich Produkt-Ratings als Variable hinzugezogen, um Nutzern anhand ihrer Bewertungen Produkte vorzuschlagen, die sie mit hoher Wahrscheinlichkeit ebenfalls positiv bewerten würden. Um ein besseres Verständnis für den technischen Workflow des benutzerdefinierten Modells zu schaffen, werden in den nächsten Abschnitten die angewandten Methoden und Verfahren sowie die technische Umsetzung des anfangs vorgestellten hybriden Empfehlungsmodells im Detail erläutert.
3.1 Bildung von Produkt-Moment-Korrelationen nach Pearson
Der Korrelationskoeffizient nach Pearson (r) ist eine einfache Möglichkeit, den Zusammenhang zweier Variablen zu bestimmen. r liegt dabei stets zwischen [-1; +1], wobei 1 einen perfekt positiven Zusammenhang und (-1) einen perfekt negativen Zusammenhang impliziert. Je näher r an 0 liegt, desto geringer ist der lineare Zusammenhang beider Variablen.
Übertragen auf einen E-Commerce Use Case würde der lineare Zusammenhang zweier oder mehrerer Produkte im Warenkorb der Transaktion betrachtet werden. Hierbei würde 1 eine starke Korrelation zwischen zwei Produkten beim Kauf bedeuten, (-1) eine negative Korrelation, sprich, dass diese Produkte nie zusammen im Warenkorb vorkommen und deshalb auch nicht von der Recommendation Engine zusammen vorgeschlagen werden sollten.
Für die Erstellung von Produkt-Moment-Korrelationen nach Pearson unterstützt BigQuery die statistische Aggregatfunktion CORR:
CORR(X1, X2 //Produkte
)[OVER (…)] //Gibt ein Fenster an
Der Korrelationskoeffizient nach Pearson kann nur lineare Zusammenhänge erkennen. Sind zwei Variablen scheinbar unkorreliert, kann immer noch ein nicht linearer (exponentieller, quadratischer) Zusammenhang bestehen. Seine Berechnung ist nur bei kardinal skalierten Daten möglich.
3.2 k-Means Clustering für Produktähnlichkeiten
Der k-Means-Algorithmus dient der Vektorquantisierung und ist eines der am häufigsten verwendeten Verfahren zur Gruppierung von Objekten (Clusteranalyse). Mit seiner Hilfe lässt sich eine bestimmte Anzahl von Objekten in homogene Gruppen unterteilen. Ziel der Clusterung ist es, dass die sich verschiedenen Objekte innerhalb einer Gruppe möglichst ähnlich sind. Der Algorithmus nähert sich dabei durch sich ständig wiederholende Neuberechnungen den jeweiligen Clusterzentren an, bis keine signifikante Veränderung mehr stattfindet.
Die optimale Anzahl an Clustern lässt sich u. a. mit der sog. „Elbow Function“ ermitteln. Die Verwendung des „Elbows“ – auch als „Knick in der Kurve“ bezeichnet – ist eine übliche Heuristik in der mathematischen Optimierung, um einen Punkt zu ermitteln, an dem das Hinzufügen eines weiteren Clusters nicht zu einer wesentlich besseren Modellierung der Daten führen würde.
3.3 XGBoost Algorithmus für Produkt-Ratings
Der Name XGBoost steht für Extreme Gradient Boosting. Es handelt sich um eine Open-Source-Bibliothek für überwachtes maschinelles Lernen mit dem sog. Baumalgorithmus mit Gradient Boosting, auch bezeichnet als Boosted-Tree-Modell. Mithilfe von XGBoost lassen sich Zielvariablen genauer bestimmen, indem mehrere einfachere und schwächere Modelle miteinander kombiniert und Schätzungen getroffen werden, entsteht eine Kombination mehrerer Regressionen zu einem starken Regressor.
Ein Boosted-Tree-Modell lässt sich in BigQuery mit der BigQuery ML Funktion CREATE MODEL und dem den Modell-Type BOOSTED_TREE_CLASSIFIER oder BOOSTED_TREE_REGRESSOR erstellen. Der Datensatz wird anschließend durch das Modell mit der XGBoost-Bibliothek trainiert.
3.4 Technischer Workflow

① Übermittlung der GA4 Daten
Als Datenbasis werden die Warenkorb-Informationen (Product, Items) aus dem Standard Ecommerce-Objekt des Google Analytics Transaktions-Event genutzt. Diese werden im Rahmen eines täglichen Uploads der GA4-Daten über ein BigQuery Table zur Verfügung gestellt. Als Matching-Key dient die von Google Analytics generierte visitor_id (cid) oder eine aus dem CRM generierte user_id.
Falls verfügbar, ist die Verwendung einer user_id vorzuziehen, da diese beständiger ist, einen realen Nutzer identifiziert und in den meisten Fällen generell während des Check-outs erstellt wird.
② Berechnung der Produkt-Moment-Korrelationen
Zunächst erfolgt die Feststellung von Produkt-Moment-Korrelationen innerhalb der Warenkörbe einzelner Transaktions-Events. Der Wert berechnet sich aus der Summe aller Warenkörbe sowie der Häufigkeit von Kombinationen einzelner Produkt IDs im Warenkorb selbst. Das ermöglicht Erkenntnisse darüber, wie stark sich einzelne Produkte im Warenkorb bedingen.
Das Korrelationsschema kann bspw. anhand historischer Daten für die Top 20 Produkte auf Tagesbasis durchgeführt werden. Die Berechnung der Produkt-Moment-Korrelationen bildet dabei die Grundlage für die weitere Clusteranalyse und das Training des Datensatzes durch Verfahren des maschinellen Lernens. Im Vergleich zu einer End-to-End-Lösung besteht hier vollständige Kontrolle über den Input für den Algorithmus und vollständige Transparenz über den Prozess zur Auslieferung der personalisierten Empfehlungen.
③ Clusteranalyse mit k-Means
Auf Grundlage ermittelter Produkt-Warenkorb-Korrelationen wird über die CREATE MODEL Funktion in BigQuery eine k-Means Clusteranalyse durchgeführt. Die Analyse weist anschließend homogene Produkt-Warenkorb-Kombinationen einzelnen Clustern zu.
④ Product Ratings mit dem XGBoost Algorithmus
Über BigQuery ML wird ein XGBoost Algorithmus trainiert, welcher auf Grundlage retrospektiver Product Ratings einzelne Nutzer Wahrscheinlichkeiten für zukünftige Product Ratings homogener Produkte vorhersagt. Produkt-Empfehlungen werden hierbei unter der Annahme ausgegeben, dass Nutzer homogene Produkte zukünftig gleich bewerten werden.
⑤a Übermittlung der Produkt Empfehlungen (CMS Plugin)
Falls vorhanden, wird die Produktempfehlung an ein Shop-Plugin übergeben, welches die Auslieferung der Produktempfehlungen für den Nutzer übernimmt.
⑤b Aufruf der Cloud Function
Es wird eine Cloud Function getriggert, welche die Produkt-Empfehlungen an den auf der Website implementierten Google Tag Manager ausgeliefert.
⑥ Aufruf des Google Tag Managers
Der Google Tag Manager pusht die ausgelieferten Produkt-Empfehlungen anschließend in das dataLayer- Object.
⑦ Übermittlung der Produkt Empfehlungen
Über das dataLayer-Object können Onsite-Optimierungstools wie bspw. Google Optimize auf die Product- Empfehlungen für den spezifischen Nutzer zugreifen und anschließend ausspielen.
4. Empfehlung
Wie bereits im Vorwort beschrieben, lässt sich mit einer vorhandenen End-to-End-Standardlösung kein Wettbewerbsvorteil erreichen. Hinzu kommt die fehlende Transparenz sowie Kontrolle über Abläufe innerhalb der Recommendation Engine. End-to-End-Lösungen sollte daher nur in Betracht gezogen werden, falls in der Individualisierung für Interessenten kein Mehrwert im Marketing gesehen wird, wobei diese Einstellung sicherlich zu hinterfragen wäre. Falls eine bessere und individuelle Ansprache von Interessenten gewünscht ist, sollte in Betracht gezogen werden, eine Recommendation Engine individuell für das eigene Geschäft aufzubauen. Moderne Cloud Technologien bieten hierfür die besten Voraussetzungen.